Google Sheets has a formula that lets you scrape values from a website: =importxml().
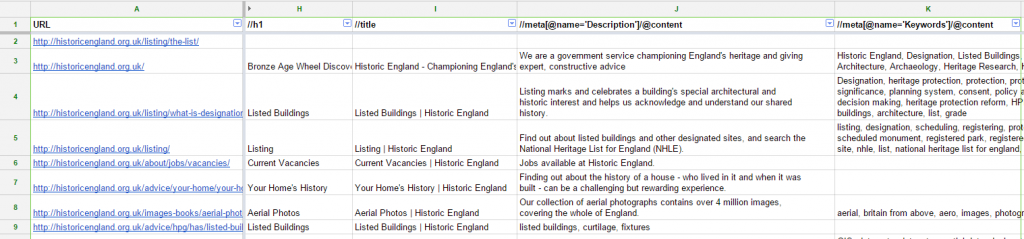
Get a list of your web pages (you can do this by importing your xml sitemap into Google Sheets) and then use the =importxml() formula to scrape values for things like metadata title and description, or on-page text like your Heading 1.
Importxml(URL,Xpath)
Importxml has two parameters:
URL: is your web page address
XPATH: is the description of the content you’re requesting. w3schools.com has a pretty useful overview of the syntax.
Fetch individual metadata values
Assuming you have the URL in column A, and column headings in row 1, the formulas you would use starting from row 2 are:
H1:
=importxml(A2,"//h1")
Browser Title
=importxml(A2,"//title")
Description
=importxml(A2,"//meta[@name='Description']/@content")
Keywords
=importxml(A2,"//meta[@name='Keywords']/@content)
There seems to be a hidden speed limit; I find that the first few hundred fields will populate really quickly but then it really slows down to just one cell updating every 10-20 seconds. Making a cup of tea or writing a blog post about it can help kill the time.
Fetch multiple values in one request
You can fetch multiple values in a single request. I presume this will help speed up the process but I don’t have it working reliably enough to use it in place of the above method.
Use a pipe separater in the XPATH value to request more than one item.
Fetching the H1 and Title in a single request can be done like this:
=importxml(A2,"//h1 | //title")
The first thing to be aware of is that this will bring each value in as a new row. To convert that to columns instead wrap the formula in =transpose():
=transpose(importxml(A2,"//h1 | //title"))
The problem I find with this method is that it gives the results in the order they appear on the page, not the order you request them.
For example the following formula doesn’t bring back keywords first:
=transpose(importxml(A1,"//meta[@name='Keywords']/@content | //h1 | //title | //meta[@name='Description']/@content"))
For me it returns Title, Description, Keywords, H1 because that’s the order in the HTML I’m scraping.
The bigger problem is that where a field doesn’t exist, its column doesn’t get skipped. Where keywords are blank it doesn’t leave a blank cell, it shifts the H1 into the column that contains keywords for other pages.
You can only really use this then for fields you know will be filled in.
My workflow for scraping metadata values
The value gets cached in Google Sheets for a few hours before it will fetch new content. Before this happens you should copy and paste as values to overwrite the formula with the content it fetched.
My process is:
- Get the URL list prepared, perhaps sorted by priority (such as an audit of most viewed pages, or all level 1 & 2 landing pages)
- Put the formulas in for the first page, and drag the formulas down to autofill about 50 rows.
- Wait for Google Sheets to fetch the values and then select all but the last row (e.g. rows 2-49 if you had filled the formula to row 50)
- Copy and Paste special: Paste values only
- Drag the formula from your last rown down about 50 rows
- Repeat 3-5